扰动
一直都有在深层神经网络的输入中加入扰动来误导分类结果的说法,之前听说的都是随机扰动。最近看到一篇论文,使用了全局的扰动来干扰分类器,效果十分可怕。
论文在arxiv中有提供:
Universal adversarial perturbations
直接上效果
-
看个示意图
 左边是正确分类,右边是错误分类。看不出来吧~~
左边是正确分类,右边是错误分类。看不出来吧~~ -
扰动长什么样
针对不同网络模型在imagenet那个数据集训练的扰动长这样:
-
扰动之后长什么样
仔细看还是可以看见波纹的。
-
数据说明问题
表中的所有数据都是错误率!
首先这些扰动是可以共用的,虽然效果没有专用的好: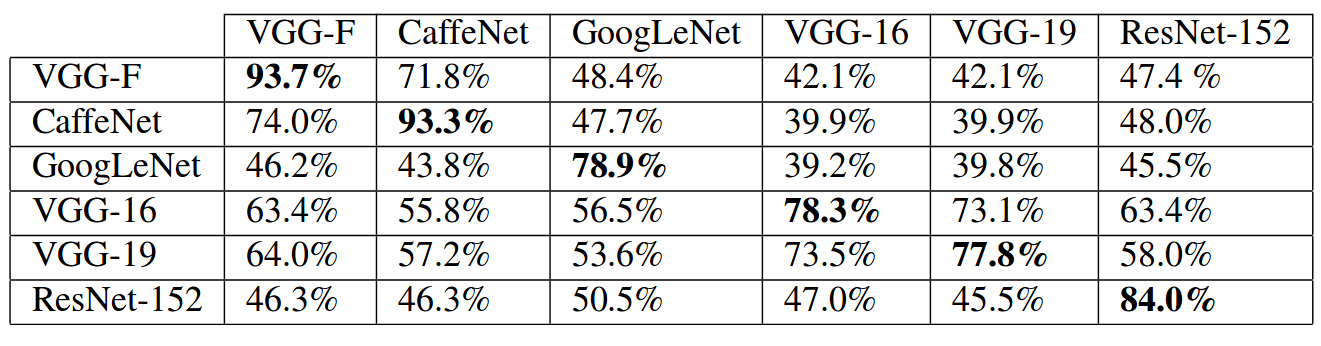 专用大概是这样:
专用大概是这样:

关于算法
- 大概就是这样:
 所以针对同一种网络模型,算出来的扰动向量可以有很多种。
所以针对同一种网络模型,算出来的扰动向量可以有很多种。
针对这些扰动的fine-tuning有用吗
- 几乎没有。
- 事实上,不考虑迭代次数,这样做也只能把错误搞到80%左右。(
还是很高)
全局扰动比随机的扰动要好
- 至于为什么,我也看不懂。
- 大意是全局扰动的泛化能力更好,只用很少图片训练的扰动向量就有不错的效果。